실험실에서 초파리를 키우다 보면 누구나 예외 없이 ‘레퍼런스 스트레인’이라는 개념과 마주하게 된다. Canton-S든 w1118이든, 우리는 어떤 돌연변이의 표현형을 판단할 때마다 이 야생형을 기준점으로 삼는다. 야생형이 없다면 돌연변이는 그저 ‘다르다’는 사실 하나만 남을 뿐, 무엇으로부터 얼마나 벗어났는지는 말할 수 없다. 인큐베이터 옆 병에 놓인 야생형 스톡을 볼 때마다, 나는 이것이야말로 유전학이라는 학문 전체를 떠받치는 가장 조용한 기둥이라고 생각해왔다.

버거의 세계에도 그런 기준점이 있다는 걸, 최근 한 논문을 읽으며 새삼 깨달았다. 바로 빅맥이다. 100개국 넘는 나라에서 팔리고, 심지어 이코노미스트지가 각국 통화의 실질구매력을 비교할 때 쓰는 ‘빅맥 지수’의 표준이 될 정도로, 빅맥은 지구상에서 가장 널리 공유된 ‘레퍼런스 버거’다. 지난 6월 26일, 스탠퍼드 연구팀이 이 레퍼런스 버거를 정면으로 겨냥한 논문을 npj Science of Food에 발표했다. 제목부터 노골적이다. “생성형 인공지능이 맛있고 지속가능하고 영양가 있는 버거를 만든다.” 기계공학과의 엘렌 쿨(Ellen Kuhl) 교수—지금은 스탠퍼드의 학제간 생명과학 기관 Bio-X를 이끌고 있다—와 슈미트 사이언스 펠로우 바히둘라 타치(Vahidullah Tac), 스탠퍼드 의대 예방연구센터의 크리스토퍼 가드너(Christopher Gardner)가 함께 썼다. 이 팀에게 이번이 처음은 아니다. 쿨 교수는 이미 작년에 같은 학술지에 AI와 음식 연구를 다룬 논문을 발표했고, 육류와 대체육의 역학적 물성을 비교하는 연구도 해왔다. 버거는 그 연장선에서 고른, 의도적인 ‘모델 시스템’이다. 논문 초록이 실제로 이 표현을 그대로 쓴다.
레시피를 어떻게 데이터로 만들 수 있을까. 이들은 두 단계로 나눴다. 첫 단계는 어떤 재료가 들어가는가—146개 재료 각각에 대한 있다/없다의 이진 변수를 다루는 다항 확산 모델(multinomial diffusion model)이다. 둘째 단계는 그 재료가 얼마나 들어가는가—연속값인 양을 다루는, 확률미분방정식 기반의 점수 기반 확산 모델(score-based diffusion model)이다. 존재 여부와 정도를 분리해서 모델링한다는 이 발상 자체가 유전학자에게는 낯설지 않다. 유전자좌마다 어떤 대립유전자가 있는지를 정하는 일과, 그 유전자가 얼마나 발현되는지를 정하는 일은 원래 다른 문법을 갖는다. 훈련 데이터는 레시피 사이트 Food.com의 52만 2517개 레시피에서 시작했다. 이 가운데 버거로 분류될 만한 것들을 LLM과 키워드 필터링으로 골라내고, 재료명을 정규화하고, 드문 재료를 솎아내는 과정을 몇 차례 반복했다. 단일세포 시퀀싱 데이터를 다뤄본 사람이라면 익숙할, 그 지긋지긋한 품질관리(QC) 파이프라인과 꼭 닮았다. 결과는 2,216개 레시피, 146개의 고유 재료로 이뤄진 깔끔한 데이터셋이었다.
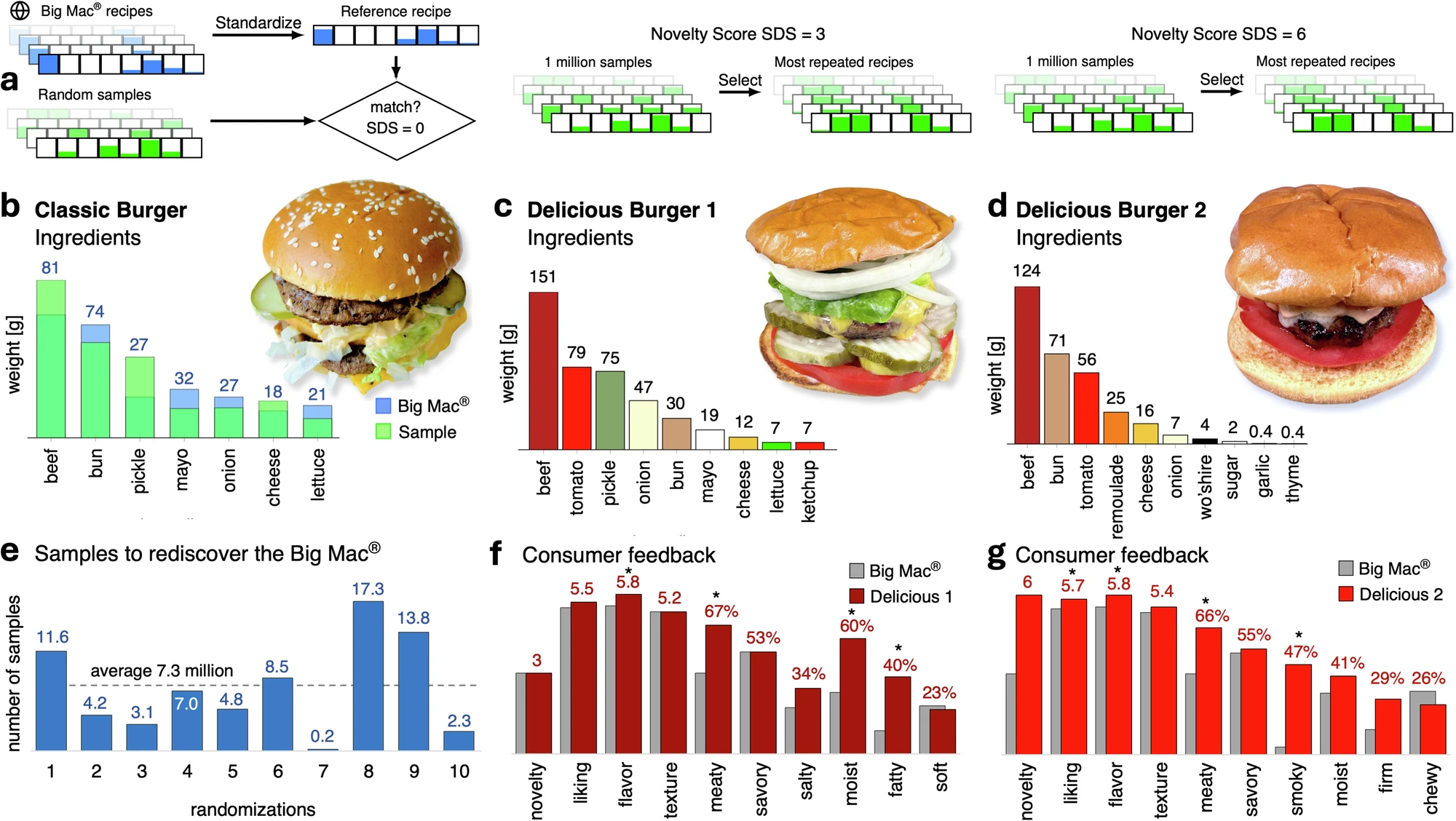
모델을 정말 신뢰할 수 있는지 검증하려면 어떻게 해야 할까. 연구팀은 유전학자라면 반사적으로 이해할 전략을 썼다. 양성대조군이다. 다만 이번 대조군은 실험실 스톡이 아니라 빅맥이었다. 빅맥의 정확한 레시피는 기업 기밀이라 공식적으로 알려져 있지 않다. 그래서 이들은 온라인에 떠도는 네 가지 독립적인 ‘빅맥 재현’ 레시피를 종합해 근사 레시피를 만들었다. 500킬로칼로리 기준으로 소고기 81g, 번 74g, 마요네즈 32g, 피클 27g, 양파 27g, 양상추 21g, 치즈 18g. 이 조합은 훈련 데이터에 단 한 번도 등장하지 않았다. 그런데 모델이 무작위로 레시피를 계속 생성하다 보면, 재료 구성이 정확히 일치하고 비율도 비슷한 조합이 튀어나온다. 열 번의 독립 시행에서 평균 730만 개의 샘플을 뽑아야 이 ‘재발견’이 일어났다. 730만분의 1이라는 확률은 아득해 보이지만, 뒤집어 생각하면 놀라운 이야기다. 어떤 명시적 지도도 없이, 순수하게 인간이 실제로 만들어 먹은 레시피들의 통계적 구조만으로, 지구상에서 가장 유명한 버거의 정확한 배합비가 백만 분의 몇이라는 확률로 다시 나타난다는 뜻이니까.
이제 진짜 흥미로운 질문이 남는다. 모델이 빅맥을 재발견할 수 있다면, 빅맥이 아닌 것도 만들어낼 수 있을까? 연구팀은 ‘실질적 차이 점수(Substantial Difference Score, SDS)’라는 지표로 새로움의 정도를 정량화했다. 146개 재료 각각에 대해 두 레시피가 유의하게 다른지—있다/없다가 뒤집혔거나 양이 두 배 넘게 차이 나는지—를 세어 합산하는 방식이다. 나는 이게 정확히 두 유전형 사이의 해밍 거리(Hamming distance)와 같은 논리로 읽혔다. 146개 유전자좌 중 몇 개가 다른가를 세는 것과 다를 게 없다. SDS를 3 이상, 6 이상으로 설정해 뽑아낸 ‘딜리셔스 버거’ 두 종을 실제 셰프가 조리해, 샌프란시스코의 한 레스토랑에서 101명을 대상으로 블라인드 관능평가를 진행했다. 결과는 분명했다. 두 버거 모두 빅맥과 동등하거나 그 이상의 만족도를 받았다. 한 버거는 풍미에서 유의하게 높은 점수(7점 만점에 5.8 대 5.4)를 받았고, 참가자들은 이 버거를 빅맥보다 더 ‘고기 맛이 난다'(67% 대 42%)고, 더 ‘촉촉하다'(60% 대 32%)고 표현했다.
여기서 나는 하나의 질문을 던지고 싶어진다. 이건 정말 ‘창조’일까, 아니면 ‘재조합’일까. 이 모델이 하는 일은 결국, 인간이 이미 시도했던 조합들의 학습된 확률분포 안에서, 크게 벗어나지 않는 새로운 조합을 뽑아내는 것이다. 존재하지 않던 재료나 조리법을 발명하는 게 아니다. 초파리 유전학자에게 이건 낯선 현상이 아니다. 개체군 안에서 관찰되는 표현형 변이의 대부분은 새로운 돌연변이가 아니라, 이미 존재하는 대립유전자들의 재조합에서 나온다. 재조합만으로도 방대한 표현형 공간이 열린다는 걸 우리는 이미 안다. 이 논문이 보여주는 ‘창조성’도 아마 그런 종류일 것이다. 돌연변이가 아니라 재조합. 그리고 그건 결코 하찮은 창조성이 아니다. 진화도 대개 그렇게 작동한다.
지속가능성 쪽 이야기는 더 냉정하다. 훈련 데이터를 들여다보면 양고기와 소고기 기반 레시피는 가금류나 버섯 기반 레시피보다 체계적으로 높은 환경영향점수(Environmental Impact Score)를 보인다. 토지 이용, 부영양화, 물 부족, 온실가스 배출을 종합한 지표다. 모델이 이 점수가 낮은 쪽으로 백만 개의 레시피를 걸러내자, 포토벨로 버섯이 주재료인 ‘서스테이너블 버거’가 나왔다. 환경영향점수는 빅맥보다 한 자릿수 이상 낮았다. 논문 초록의 표현 그대로다. 그런데 관능평가는 정직했다. 이 버섯 버거는 만족도, 풍미, 식감 모두에서 빅맥보다 유의하게 낮은 점수를 받았다. ‘흙 맛이 난다’고 응답한 비율이 63%였다(빅맥은 2%). 연구팀은 이걸 감추지 않고 그대로 실었다. 대신 소고기와 버섯을 함께 쓴 두 번째 버전은 관능 점수에서 빅맥과 차이가 없었다. 환경 점수는 크게 달라지지 않았지만, 맛을 포기하지 않고도 버섯을 슬쩍 섞어 넣는 길이 있다는 걸 보여준다.
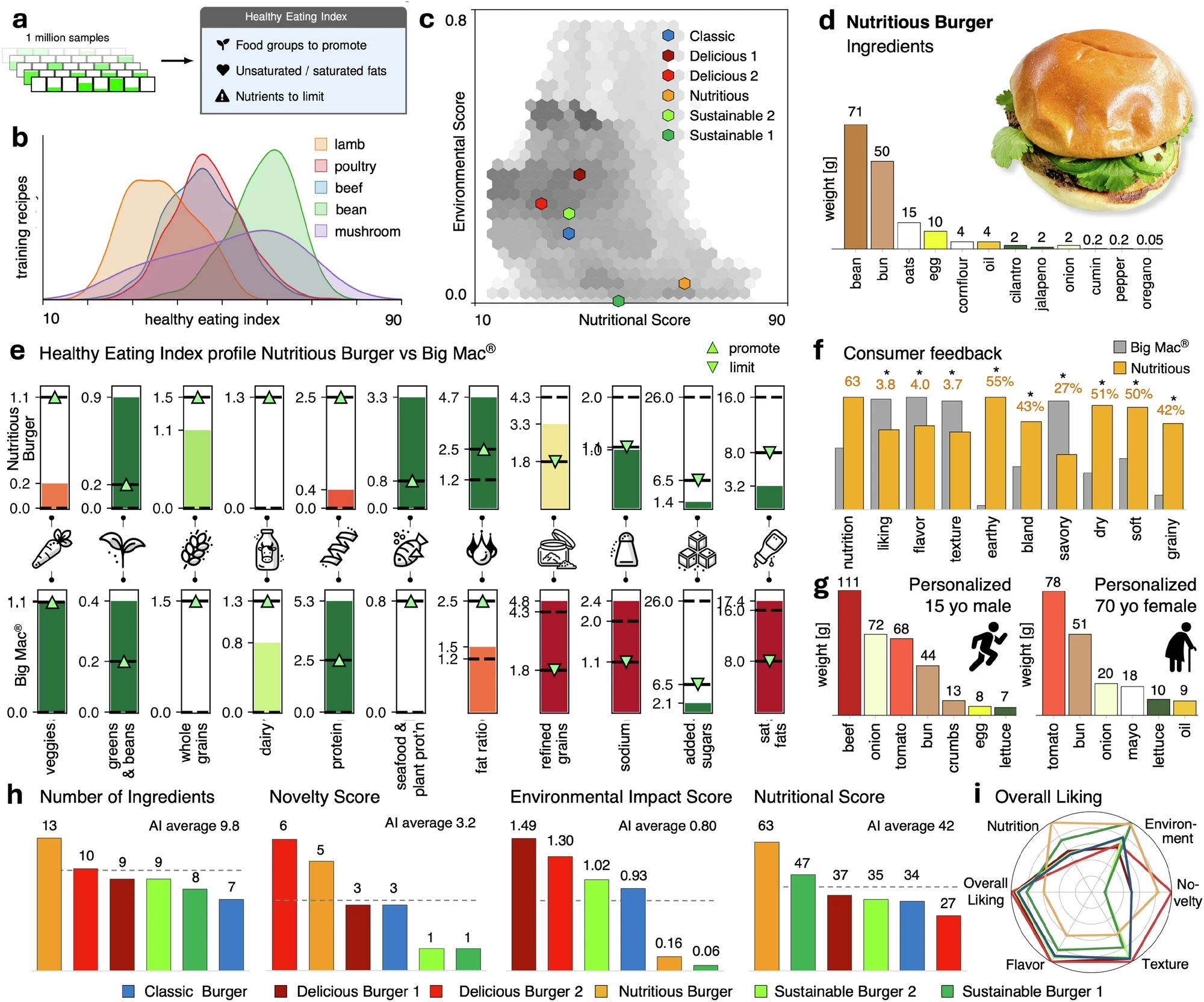
영양 쪽이야말로 이 논문에서 가장 정직한 대목이라고 나는 생각한다. 콩을 주재료로 한 ‘뉴트리셔스 버거’는 건강 식생활 지수(Healthy Eating Index)에서 63.12점을 받아, 빅맥의 33.71점을 거의 두 배 가까이 앞섰다. 환경영향점수도 6분의 1로 줄었다. 지속가능성과 영양이 반드시 서로 배타적이지 않다는 걸 보여주는 결과다. 하지만 맛은—만족도(3.8 대 5.3), 풍미(4.0 대 5.4), 식감(3.7 대 5.2) 모두 빅맥보다 유의하게 낮았다. 사람들은 이 버거를 밍밍하고, 퍽퍽하고, 알갱이가 씹힌다고 묘사했다. 아무리 정교한 AI라도 건강함과 맛있음 사이의 오래된 긴장을 완전히 해소하지는 못했다. 나는 이걸 논문의 흠이 아니라 미덕으로 읽는다. 팔리는 이야기를 위해 불편한 데이터를 감추지 않는 것. 그게 바로 우리가 매일 씨름하는 연구 진실성의 문제 아닌가.
이 모델은 개인의 나이, 성별, 활동량에 따라 영양 목표를 다르게 설정하고, 그에 맞춘 ‘개인 맞춤형 버거’까지 만들어낸다. 활동량이 많은 15세 소년과 활동량이 보통인 70세 여성을 위한 레시피는 재료 구성부터 다르다. 정밀의학이 개인의 유전형에 맞춰 처방을 조정하듯, 정밀영양학도 이제 개인의 생리적 프로필에 맞춰 한 끼의 조성을 조정하는 단계로 가고 있는 셈이다.
논문이 스스로 인정하는 한계도 짚어둘 만하다. 모델은 인간이 만든 레시피에서만 배우기 때문에, 그 데이터에 깃든 문화적·지역적 편향을 그대로 물려받는다. 조리법이나 가공 과정은 아예 모델링 대상이 아니다. 이 AI가 내놓는 건 재료와 중량의 목록일 뿐, ‘어떻게 구울 것인가’는 다루지 않는다. 그래서 연구팀은 저스틴 슈나이더라는 총주방장을 따로 고용해, AI가 뱉어낸 숫자 목록—이를테면 오레가노 0.05그램 같은 것—을 실제로 구현 가능한 조리 지침으로 번역해야 했다. AI가 설계하고, 인간이 요리한다. 나는 이 그림이 마음에 든다.
이 논문의 저자들이 강조하는 더 큰 그림은 이렇다. AI를 ‘무엇이 이미 있는가를 예측하는 도구’에서 ‘무엇이 있어야 하는가를 설계하는 도구’로 옮기는 것. 지금까지 대부분의 생성형 AI는 기존 패턴을 재현하는 데 최적화되어 있었다. 이 연구는 그 틀 위에 맛있음·지속가능성·영양이라는 명시적 목적함수를 얹어 탐색 공간을 다시 정의했다. 나는 이 발상을 자꾸 우리 실험실로 가져와 보게 된다. 우리가 수천 개의 유전자 조합, 신경회로 조합, 행동 표현형 조합을 스크리닝할 때, 우리도 결국 ‘가능한 조합의 초거대 공간’ 안에서 원하는 표현형을 찾고 있는 셈이다. 언젠가 생성형 모델이 생존 가능하고 기능적인 유전형-표현형 조합의 분포를 학습해서, 우리가 원하는 신경 회로나 행동에 가장 가까운 재조합 유전형을 제안해주는 날이 올까. 버거의 재료 조합 공간이—쿨 교수가 언론 인터뷰에서 언급한 추정치로는—10^43 가지에 이른다면, 초파리 게놈이 만들어낼 수 있는 조합 공간은 그보다 또 얼마나 더 클지 가늠하기도 쉽지 않다.
논문을 덮고 나니, 다음에 인큐베이터 옆에서 야생형 스톡 병을 집어들 때는 조금 다른 생각이 들 것 같다. 그 병 속 파리들도 결국 하나의 레퍼런스이고, 우리가 만드는 모든 돌연변이는—크건 작건—그로부터의 재조합이자 이탈이다. 빅맥이 버거의 세계에서 하는 일을, 그 병 속의 파리들은 우리 실험실에서 조용히 해내고 있었다. 어쩌면 언젠가 우리도 우리만의 점수 기반 확산 모델을 갖게 될지 모른다. 다만 우리가 최적화하려는 건 풍미가 아니라, 살아 있는 신경계일 뿐이다.
참고문헌 Tac, V., Gardner, C.D. & Kuhl, E. Generative artificial intelligence creates delicious, sustainable, and nutritious burgers. npj Science of Food 10, 199 (2026). https://doi.org/10.1038/s41538-026-00953-x
You must be logged in to post a comment.