

초파리 유전학자에게는 오래된 습관이 하나 있다. 실험에 필요한 계통이 생기면 그 계통을 가진 실험실에 편지를 쓰거나, 블루밍턴의 스톡센터에 주문을 넣는다. 며칠 뒤 작은 바이알이 도착한다. 배지 위에서 이미 알을 낳기 시작한 성충 몇 마리, 그것이 전부다. 비용은 계통을 살려두고 부치는 데 드는 실비에 가깝다. 나는 그 바이알을 받아 계대하고, 교배하고, 표현형을 읽는다. 몇 해가 걸릴지 모르는 실험이 그렇게 시작된다.
이 관행에는 백 년의 내력이 있다. 컬럼비아의 좁고 지저분한 방에서 토머스 헌트 모건과 그의 학생들이 흰눈 돌연변이를 붙잡았을 때부터, 초파리 연구자들은 자기가 만든 돌연변이를 남에게 보내는 일을 당연하게 여겼다. 캘빈 브리지스가 유지하던 계통들, 스터티번트가 그린 최초의 유전자 지도, 그 뒤로 이어진 수만 개의 계통과 FlyBase라는 이름의 거대한 공용 데이터베이스. 초파리 공동체가 20세기 유전학의 절반을 만들어낸 것은 그 구성원들이 유독 영리해서가 아니라, 자기가 가진 것을 내놓는 것이 규범이었기 때문이다. 계통은 사유물이 아니라 공동체의 자산이었다. 이 규범이 없었다면 유전자 지도도, 호메오박스도, 시계 유전자도, 선천면역의 톨 경로도 지금과 같은 속도로 오지 못했을 것이다.
그런데 그 바이알로 얻은 결과를 세상에 내놓는 데에는 전혀 다른 계산서가 붙는다. 오늘 기준으로 Nature에 오픈액세스로 논문을 실으려면 저자는 12,850달러를 낸다. Nature Communications는 7,350달러, The Lancet은 1만 달러를 넘는다. 상대적으로 저렴하다는 PLOS ONE조차 2,477달러다. 원고를 받아 심사에 돌리고 편집하고 조판해 인터넷에 올리는 일의 값이다. 바이알은 실비에 오가는데, 그 바이알로 쓴 논문을 공개하는 값은 초파리 계통 수백 개를 주문할 수 있는 액수다. 이 비대칭이 최근 미국 연방법원에서 정면으로 다뤄지기 시작했다.
2026년 7월 30일, 매사추세츠 연방지방법원이 2년 넘게 봉인해두었던 소장 하나의 봉인을 풀었다. 사건명은 United States ex rel. Juan Pablo Alperin v. Elsevier et al.이고, 사건번호는 1:24-cv-10603-ADB다. 원고 자리에 미국 정부의 이름이 먼저 오는 것은 이것이 부정청구법(False Claims Act), 이른바 링컨법에 근거한 퀴탐(qui tam) 소송이기 때문이다. 남북전쟁 당시 군납업자들이 썩은 고기와 모래 섞인 화약을 팔아먹는 것을 막으려고 만든 이 법은, 정부를 속여 돈을 받아낸 자를 사인이 대신 고발하고 회수액의 일부를 보상으로 받는 구조를 갖는다. 지금은 주로 제약회사와 병원의 의료보험 사기를 잡는 데 쓰인다. 학술출판사가 이 법정에 불려나온 것은 처음이다.

피고는 Elsevier, Springer Nature, Wiley, 그리고 Taylor & Francis의 모회사인 Informa 네 곳이다. 원래 피고 목록에 있던 Sage는 봉인 해제 직전에 빠졌다. 고발인은 사이먼프레이저대학의 후안 파블로 알페린으로, 학술커뮤니케이션 연구실을 공동으로 이끌면서 오랫동안 APC 가격을 실증적으로 분석해온 사람이다. 그가 오픈액세스 출판사 협회의 회원 자격으로 알게 된 내부 사정, 즉 출판사들 사이에 오간 논의와 “무료 오픈액세스 선택지의 실현 가능성을 가리는” 전략이 소장의 근거로 제시되었다고 한다.
법리 구조는 우회적이지만 낯설지 않다. 출판사가 정부에 직접 청구서를 보내는 것은 아니다. 미국 연구자가 NIH나 NSF의 연구비로 APC를 결제하면, 그 비용은 소속 기관을 통해 연방정부에 정산된다. 연방 보조금 비용원칙은 출판비를 인정하되 그 비용이 “합리적”일 것을 요구한다. 소장의 주장은, 출판사들이 실제 처리비용의 최대 열 배에 이르는 요금을 매기면서 그 돈이 연방 연구비에서 나온다는 사실을 알고 있었고, 따라서 미국의 연구기관들이 정부에 허위 청구를 제출하도록 “야기”했다는 것이다. 제약회사가 도매가를 부풀려 병원이 메디케어에 과다청구하게 만든 사건들에서 확립된 논리를 그대로 가져온 셈이다. 소장은 출판사들이 시장을 고착시켜, 경력을 위해 명성 있는 저널에 실어야 하는 연구책임자들로부터 “명성 가격, 사치품 가격”과 저작권을 사실상 강탈하고 있다고 표현한다고 전해진다.
여기서 한 가지를 분명히 해둘 필요가 있다. 나는 소장 원문을 직접 읽지 못했다. 공개된 소장 파일은 텍스트가 아니라 이미지로 스캔된 형태였고, 이 사건을 보도한 매체는 지금까지 확인되는 한 리트랙션 워치 한 곳이다. 총 손해배상 청구액이 얼마인지, 연방 연구비에서 나간 APC 총액을 얼마로 잡았는지, 어떤 세부 법리를 택했는지는 확인되지 않았다. 위에 인용한 표현들도 모두 그 보도에서 재인용한 것이다. 이 글에서 소송에 관한 서술은 그 한 겹의 불확실성을 안고 있다고 읽어주기 바란다. 반대로 아래에 이어지는 숫자들은 사정이 다르다. 그것들은 여러 해에 걸쳐 여러 연구자가 독립적으로 계산해온 것이고, 출판사 자신이 주주에게 공시한 것이다.
논문 한 편을 출판하는 데 실제로 얼마가 드는가. 알렉산더 그로스만과 비외른 브렘브스가 2021년 F1000Research에 발표한 계산이 지금도 이 논의의 기준선이다. 두 사람은 원고 접수와 관리, 심사 조직, 편집과 조판, 색인과 영구 보존까지 각 단계의 시장 가격을 하나씩 쌓아올렸다. 결과는 게재 후 심사 방식의 대형 플랫폼에서 논문당 200달러 미만, 거절률이 90퍼센트를 넘는 최상위 저널에서 1,000달러 안팎이었다. 평균적인 논문 한 편의 비용은 대략 400달러. 소장이 주장하는 “200달러에서 1,000달러 사이”라는 수치는 이 계산과 정확히 겹친다. 두 저자 모두 학술출판 개혁 진영에 속한 사람들이고 그로스만은 출판 플랫폼의 공동창업자이니, 이 추정을 최저치로 놓고 보아도 400달러와 12,850달러 사이의 간극은 설명하기 어렵다.
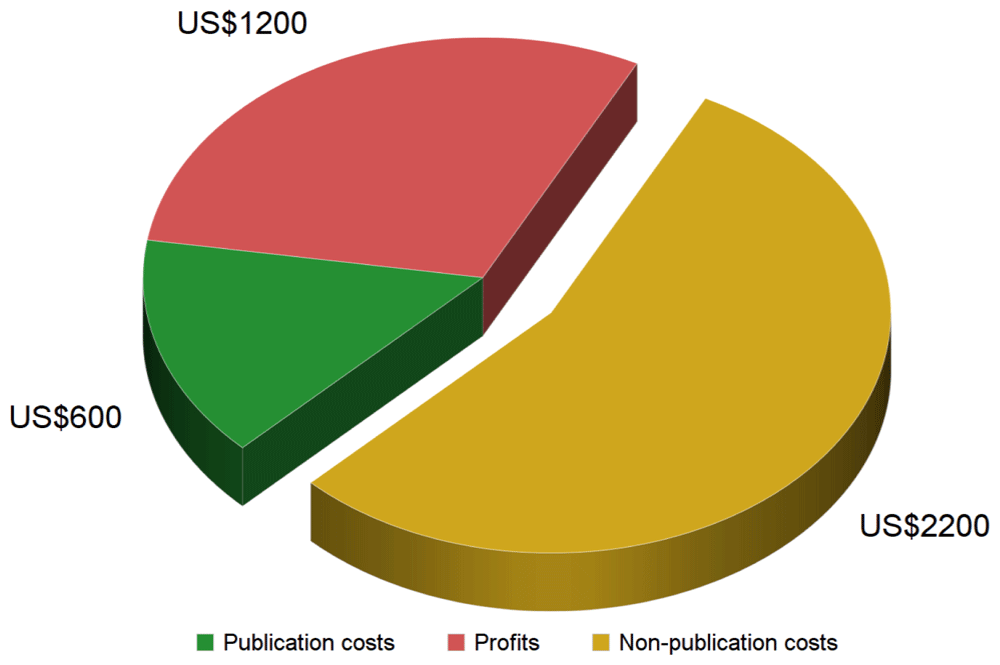
그 간극이 어디로 가는지는 공시자료가 말해준다. Elsevier의 모회사 RELX는 2024년에 그룹 전체 매출 94억 파운드에 조정영업이익 32억 파운드, 이익률 33.9퍼센트를 기록했다. 이 가운데 Elsevier가 속한 과학·기술·의학 부문은 매출 30억 5천만 파운드에 영업이익 11억 7천만 파운드, 이익률이 38퍼센트에 이른다. 제조업도 유통업도 아니고, 연구자가 무상으로 제공한 원고를 연구자가 무상으로 심사한 뒤 연구자가 소속된 기관에 되파는 사업의 이익률이다. Springer Nature는 2024년 매출 18억 유로에 영업이익 5억 유로로 28퍼센트를 기록했고, 같은 해 처음으로 1차 연구논문의 절반을 오픈액세스로 발행했다. 오픈액세스는 이제 이 산업의 부담이 아니라 성장 동력이다.
규모는 계속 커진다. 슈테파니 하우스타인과 알페린을 포함한 연구진이 2024년에 내놓은 추정에 따르면, Elsevier, Springer Nature, Wiley, Frontiers, MDPI, PLOS 여섯 출판사가 2019년부터 2023년까지 거둬들인 APC는 83억 5천만 달러다. 물가를 조정하고 나서도 연간 지출이 2019년 9억 1천만 달러에서 2023년 25억 4천만 달러로 거의 세 배가 되었다. 2023년 한 해만 놓고 보면 MDPI가 6억 8천만 달러로 가장 많았고 Elsevier가 5억 8천만 달러, Springer Nature가 5억 5천만 달러였다. 흥미로운 대목은 실제로 지불된 요금의 중앙값이 공시된 정가보다 높았다는 점이다. 이 추정치는 아직 학술지에 정식 게재되지 않은 프리프린트 상태이고, 무엇보다 이 논문의 공저자 두 사람이 곧 이 소송의 고발인과 원래의 공동고발인이었다. 자신이 계산한 숫자를 법정으로 가져간 것이다. 이해관계로 볼 수도 있고, 실증연구가 갈 수 있는 가장 먼 지점으로 볼 수도 있다.
이 산업의 원가 구조에서 가장 기묘한 항목은 원가에 잡히지 않는다. 동료심사는 무보수다. 발라즈 아첼과 동료들이 2021년에 계산한 바로는, 2020년 한 해 동안 전 세계 연구자가 동료심사에 쓴 시간이 1억 시간을 넘었다. 한 사람이 쉬지 않고 일한다면 만 오천 년에 해당한다. 이 시간을 각국의 연구자 임금으로 환산하면 미국에 소속된 심사자만 15억 달러어치, 중국이 6억 달러, 영국이 4억 달러다. 저자들은 조사에 포함된 저널이 전체의 일부이므로 이 수치가 과소추정이라고 명시했다1.
나도 이 기부에 참여한다. 대개는 실험이 끝난 밤이나 주말에, 남의 원고를 읽고 대조군의 설계를 따지고 통계의 무리를 지적하는 보고서를 쓴다. 보수는 없고 이름도 남지 않는다. 그 일을 하는 이유는 명확하다. 내 원고도 누군가 그렇게 읽어주었기 때문이고, 그 상호성이 문헌이라는 공유재를 지탱하기 때문이다. 초파리 계통을 공짜로 부치는 것과 같은 종류의 규범이다. 문제는 이 증여가 최종적으로 어디에 축적되는가에 있다. 심사자가 무상으로 만들어낸 품질 보증은 출판사의 이익률로 흘러들어가고, 다시 저자가 지불하는 12,850달러의 근거가 된다. 공동체가 스스로에게 선물한 것이 상품이 되어 공동체에 되팔린다.
APC 모델에는 구독 모델에 없던 인센티브가 하나 숨어 있다. 구독료는 논문을 몇 편 싣든 같지만, APC 수입은 수락한 논문 수에 정비례한다. 거절은 이제 비용이다. 이 구조가 무엇을 만들어내는지는 이론으로 논할 필요가 없다. 실험이 이미 끝났다.
Wiley는 2021년 초 이집트에 본사를 둔 오픈액세스 출판사 Hindawi를 인수했다. 약 250종의 저널 포트폴리오였고, 특별호를 대량으로 기획해 논문 수를 늘리는 전략이 매출을 밀어올렸다. 2023년 3월 Clarivate가 품질 기준 미달을 이유로 Hindawi 저널 19종을 Web of Science에서 퇴출했다. 두 달 뒤 Hindawi는 페이퍼밀에 심각하게 잠식된 저널 네 종의 폐간을 발표했다. 특별호 발행을 석 달간 중단하는 것만으로 9백만 달러의 매출이 사라졌다. 2022년부터 2024년 사이 이 포트폴리오에서 심사 부실을 이유로 철회된 논문이 1만 1천 3백 편을 넘는다. 학술출판 역사상 유례가 없는 규모다. 2024년 5월 Wiley는 저널 19종을 폐간했고, Hindawi라는 브랜드 자체를 없앴다.
이것을 한 출판사의 관리 실패로 읽으면 요점을 놓친다. 페이퍼밀은 수락이 매출인 시장이 열렸기 때문에 산업이 되었다. 가짜 논문을 만들어 파는 쪽과 그것을 받아 요금을 청구하는 쪽 사이에 이해가 일치하는 구간이 생긴 것이다. 그 구간에서 손해를 보는 것은 문헌을 읽고 그 위에 다음 실험을 쌓는 사람들이다. 나는 어떤 유전자의 기능을 확인하려고 논문을 뒤질 때, 그 논문이 어느 저널에 실렸는지를 예전보다 훨씬 오래 들여다보게 되었다. 이것은 시간 낭비가 아니라 자기방어다.
이 지점에서 불편한 역설을 마주하게 된다. APC를 키운 것은 오픈액세스 운동의 승리였다.
납세자가 낸 돈으로 얻은 결과를 납세자가 다시 돈을 내고 읽어야 한다는 부조리를 지적하는 데에서 오픈액세스는 시작되었고, 그 지적은 옳았다. 2022년 8월 미국 백악관 과학기술정책실은 알론드라 넬슨의 이름으로 알려진 메모를 발표해, 연방 연구비가 들어간 논문은 엠바고 없이 즉시 무료로 공개되어야 한다고 못박았다. 각 부처가 2024년 말까지 정책을 만들고 2025년 말까지 시행하도록 했다. 유럽에서는 이미 Plan S가 같은 방향으로 움직이고 있었다.
출판사들은 저항하는 대신 요금표를 바꾸었다. 구독료로 받던 것을 저자 요금으로 받기 시작했고, 구독 저널에 오픈액세스 선택지를 얹은 하이브리드 저널을 통해 같은 논문에서 두 번 수익을 냈다. 도서관 컨소시엄과 맺는 ‘읽고 출판하기’ 계약은 개별 청구를 묶어주었을 뿐 총액을 줄여주지는 못했다는 비판을 널리 받는다. 백악관이 2022년에 추산한 미국 납세자의 연간 오픈액세스 출판 부담은 3억 9천만 달러에서 7억 8천 9백만 달러였다. 논문 26만 3천 편에 편당 3,000달러를 곱한 값이다. 접근을 열라는 명령이 청구서를 만드는 명령이 된 셈이다. 덧붙이자면 이 넬슨 메모는 현 미국 행정부에서 폐지 절차에 들어간 것으로 보도되고 있는데, 기존 부처 정책들이 어떻게 될지는 아직 불확실하다. 개방의 의무만 사라지고 요금 구조는 남는 최악의 조합이 나올 가능성도 배제할 수 없다.
이 계산서에서 한국은 구경꾼이 아니다. Web of Science에 색인된 논문을 기준으로 한 분석에 따르면 한국의 APC 지출은 2019년 3천 9백만 달러에서 2023년 7천 8백만 달러로 늘었다. 연평균 18.5퍼센트다. 총액 기준으로 중국, 미국, 영국, 독일, 이탈리아, 일본, 프랑스에 이어 세계 8위다. 그런데 더 눈여겨볼 것은 총액이 아니라 배분이다. 한국은 APC 지출의 38.7퍼센트를 MDPI 한 곳에 쓴다. 이탈리아와 함께 세계에서 가장 높은 편중이다.
이 숫자는 우리 평가 체계의 초상화다. 편당 요금이 상대적으로 낮고 심사가 빠르며 SCIE에 색인된 저널로 논문이 몰린다는 것은, 연구자들이 무엇에 최적화하고 있는지를 정확히 보여준다. 3년 주기의 과제 평가와 연차 실적 보고에서 요구되는 것은 발견의 깊이가 아니라 색인된 논문의 개수다. 그 요구에 가장 효율적으로 응답하는 경로가 열려 있고, 그 경로의 통행료가 매년 18퍼센트씩 오른다. 한국연구재단이 마련한 오픈액세스 정책안이 지원 상한을 최근 3년 APC의 평균과 중앙값으로 묶고 하이브리드 저널을 지원 대상에서 빼기로 한 것은 방향으로는 옳다. 다만 요금을 통제하는 것과 요금을 지불하게 만드는 평가 체계를 손보는 것은 다른 문제다. 후자를 그대로 둔 채 전자만 조이면 연구자 개인의 부담으로 옮겨갈 뿐이다.
대안이 없는 것은 아니다. 다만 하나같이 아슬아슬하다.
Annual Reviews가 2019년에 고안한 ‘구독해서 개방하기'(Subscribe to Open) 모델은 우아하다. 도서관들이 기존 구독을 갱신해 일정 기준을 채우면 그해 발행분 전체가 오픈액세스로 풀리고 저자는 한 푼도 내지 않는다. 기준에 미달하면 유료로 남는다. 새로운 돈을 요구하지 않고 기존의 지불 흐름을 재배치할 뿐이라는 점이 이 모델의 미덕이다. 실제로 Annual Reviews는 2023년부터 3년 연속 전권 개방에 성공했고, De Gruyter Brill은 124종을, EMS Press는 22종 전부를 이 방식으로 열었다. 영국 왕립학회도 2026년부터 8종을 전환하기로 했다. 그러나 Karger는 Oxford University Press에 인수된 뒤 출판 모델을 단순화한다는 이유로 2027년부터 이 모델을 접고 하이브리드로 돌아간다. 매년 자발적 협력을 다시 확보해야 하는 구조는 소유권이 바뀌거나 도서관 예산이 조이면 곧바로 흔들린다.
저자도 독자도 내지 않는 다이아몬드 오픈액세스는 이미 방대하게 존재한다. 2021년 조사에서 전 세계에 1만 7천에서 2만 9천 종이 확인되었고 세계 논문의 8퍼센트 남짓을 담당한다. 유럽이 45퍼센트, 라틴아메리카가 25퍼센트, 아시아가 16퍼센트다. 문제는 절반 이상이 연간 25편 미만을 내는 영세 저널이고, 아프리카 조사에서는 응답 저널의 4분의 3이 재정을 최대 난제로 꼽았다는 점이다. 무료는 공짜가 아니다. 누군가의 시간과 어딘가의 예산이 대신 지불하고 있을 뿐이다.
eLife는 2023년부터 수락과 거절 자체를 없애고, 심사를 통과한 모든 원고를 공개 심사평과 함께 ‘심사된 프리프린트’로 내놓는 방식으로 바꾸었다. 게이트키핑을 포기하고 평가를 투명하게 공개하는 실험이다. 대가는 즉각적이었다. Clarivate가 2024년 10월 색인을 중단했고 이 저널은 임팩트 팩터를 잃었다. 백여 개 기관과 연구비 지원기관이 여전히 eLife 논문을 평가에 반영하겠다고 밝혔지만, 임팩트 팩터가 없는 저널에 자기 논문을 걸 젊은 연구자가 얼마나 될지는 다른 문제다.
가장 직접적인 저항은 편집자들에게서 나왔다. 2023년 4월 NeuroImage의 편집진 마흔 명이 한꺼번에 사임했다. 3,450달러의 APC를 2,000달러 아래로 낮추라는 요구를 Elsevier가 “시장이 현재 요금을 지지한다”는 이유로 거절한 뒤였다. 편집진은 비슷한 저널의 실제 원가를 1,000달러 이하로 추산했다. 그들은 MIT Press와 함께 Imaging Neuroscience를 새로 만들었다. 2024년 말에는 1972년 창간된 Journal of Human Evolution의 편집진 대부분이 저널 운영 기반이 지속적으로 잠식되었다는 성명을 내고 사임했다. 이 사임들이 보여준 것은, 이 산업에서 실제로 가치를 만드는 사람들이 계약서 어느 쪽에도 서 있지 않다는 사실이다.
정직하게 전망하자면, 알페린의 소송이 이길 가능성은 높지 않아 보인다. 근거는 두 가지다.
첫째, 법무부가 2026년 7월 23일 이 사건에 개입하지 않기로 했다. 변호사들은 이것이 사건의 실질과 무관하다고 강조하고, 실제로 2025 회계연도에는 법무부가 개입을 거절한 의료 분야 사건의 회수액이 개입한 사건을 처음으로 앞질렀다. 그래도 정부가 뒤에 서지 않은 소송이 대형 로펌 넷을 상대로 오래 버티는 일은 쉽지 않다.
둘째, 이미 한 번 진 적이 있다. 2024년 9월 UCLA의 신경과학자 루시나 우딘이 같은 출판사들을 상대로 반독점 집단소송을 냈다. 동료심사 보수를 담합해 0으로 고정했고, 원고를 한 저널에만 내도록 강제했으며, 심사 중인 원고의 공유를 금지했다는 주장이었다. 2026년 1월 30일 뉴욕 동부지방법원은 이 소송을 각하했다. 재소도 불가능한 각하였다. 판사는 출판사 협회의 윤리 원칙이 모범 관행을 모아둔 문서일 뿐이며 이를 담합의 증거로 읽는 것은 “상당한 추론의 도약”이라고 판시했다. 물론 부정청구법은 반독점법과 법리가 다르고, 알페린 사건이 이 선례에 직접 구속되지는 않는다. 그러나 법원이 이 산업의 구조를 어떻게 보고 있는지는 드러났다.
그럼에도 이 소송은 중요하다. 소송의 기능은 이기는 것만이 아니기 때문이다. 봉인이 풀린 소장 71쪽은 그동안 연구자들이 학회장 복도와 트위터에서 하던 말을 처음으로 증거 개시와 반대신문이 가능한 형식으로 옮겨놓았다. 400달러의 원가와 12,850달러의 가격 사이에서 무슨 일이 일어나는지를, 출판사가 법정에서 설명해야 하는 상황이 만들어진 것이다. 그 설명을 우리는 아직 들어본 적이 없다.
초파리 유전학이 백 년 동안 굴러온 방식과 학술출판이 지난 이십 년 동안 굴러온 방식은 정확히 반대다.
한쪽에는 증여의 장부가 있다. 계통을 만들면 나눈다. 프로토콜을 세우면 알려준다. 원고를 부탁받으면 무보수로 읽는다. 이 장부에는 채권과 채무가 기록되지 않고, 다만 자기가 받은 만큼 다음 사람에게 흘려보내는 순환이 있다. 브리지스가 계통을 나누지 않았다면 유전자 지도는 없었고, 세이무어 벤저가 행동 돌연변이체를 나누지 않았다면 시계 유전자도 없었다. 이 장부의 총액은 계산된 적이 없지만, 우리가 가진 생물학 지식의 대부분이 여기서 나왔다.
다른 쪽에는 지대의 장부가 있다. 이 장부에서 논문은 공유재가 아니라 통행료를 매길 수 있는 길목이다. 원고는 무상으로 들어오고 심사도 무상으로 이루어지지만, 그 결과물이 세상에 나가는 문에는 요금소가 서 있다. 요금은 원가가 아니라 명성으로 결정된다. 명성은 연구자들이 무상으로 제공한 것이고, 요금은 그 연구자들이 낸다. 38퍼센트의 이익률은 이 순환이 완결되었다는 뜻이다.
문제는 두 장부가 별개로 굴러가지 않는다는 데 있다. 지대의 장부는 증여의 장부를 원료로 삼는다. 무상의 심사가 없으면 명성이 없고, 명성이 없으면 요금이 없다. 그러니 이것은 두 경제의 공존이 아니라 한쪽이 다른 쪽을 먹고 자라는 관계다. 그리고 먹히는 쪽에서는 이미 균열이 보인다. 심사 요청을 거절하는 동료가 늘고 있고, 편집자들이 저널을 버리고 나가며, 어느 저널에 실린 논문인지에 따라 데이터를 믿을지 말지를 먼저 판단해야 하는 상황이 되었다.
한 문명이 자기가 발견한 것들의 기록을 어떻게 다루는지는 그 문명이 지식을 무엇으로 여기는지를 말해준다. 알렉산드리아 도서관에 배가 들어오면 실려 있던 두루마리를 압수해 필사한 뒤 사본을 돌려주었다는 이야기가 전한다. 원본은 도서관이 가졌다. 옳고 그름을 떠나, 그것은 기록을 축적해야 할 것으로 여긴 자의 태도였다. 오늘 우리는 기록을 통행료를 걷을 수 있는 자산으로 여기는 체제 안에서 연구한다. 내가 블루밍턴에서 받은 바이알 속의 초파리들은 백 년 전 누군가가 만들어 아무 조건 없이 넘긴 것의 후손이다. 그 후손들로 얻은 결과를 세상에 내놓는 데 1만 2천 달러가 든다는 사실은, 어느 지점에선가 우리가 장부를 잘못 옮겨 적었다는 뜻이다.
매사추세츠의 법정이 그 잘못을 바로잡아주지는 못할 것이다. 법은 언제나 뒤늦게 도착하고, 이번에도 늦었으며, 아마 질 것이다. 하지만 잘못 적힌 장부를 소리 내어 읽는 일에는 그 자체의 값이 있다. 우리가 무엇을 공짜로 주고 있는지, 그리고 그 공짜가 어디로 흘러가 얼마가 되어 돌아오는지를 한 번은 숫자로 확인해야 한다. 그다음에 무엇을 할지는 법정이 아니라 우리가 정할 일이다.

- Butler, L.-A., Matthias, L., Simard, M.-A., Mongeon, P., & Haustein, S. (2023). “The oligopoly’s shift to open access.” Quantitative Science Studies 4(4):778–799. DOI: 10.1162/qss_a_00272. Big Five(Elsevier, Sage, Springer Nature, Taylor & Francis, Wiley)에 2015~2018년 저자들이 지불한 APC를 $1.06 billion으로 추산(gold OA $612.5M, hybrid $448.3M). 출판사별로 Springer Nature $589.7M, Elsevier $221.4M, Wiley $114.3M, Taylor & Francis $76.8M, Sage $31.6M. DNTB
Haustein, S., Schares, E., Alperin, J.P., Hare, M., Butler, L.-A., & Schönfelder, N. (2024). arXiv:2407.16551. Elsevier·Frontiers·MDPI·PLOS·Springer Nature·Wiley 6개사에 2019~2023년 총 $8.349 billion($8.968 billion in 2023 USD) APC 지출. 인플레 조정 후 연 지출이 2019년 $910.3M → 2023년 $2.538 billion으로 거의 3배. 2023년 개별 최다는 MDPI $681.6M, Elsevier $582.8M, Springer Nature $546.6M. 흥미롭게도 hybrid 요금이 gold를 초과하고, 실제 지불된 median APC가 게시 요금(list fee)보다 높았다. ↩︎